
AWS Certified Developer – Associate(DVA) 対策として、Amazon DynamoDBの特徴をまとめました。
DynamoDBとは
サーバーレス、フルマネージド、key-value型のNoSQLデータベースサービス。
DynamoDBのコアコンポーネント
DynamoDBのコアコンポーネントは、テーブル、項目、属性の3つ。
例えば、以下のUsersテーブルを例に考えてみる。
- テーブル(赤枠):SQLと同様にDynamoDBもデータをテーブルに保存する
- 項目(緑枠):テーブルは0以上の項目で構成される。属性の集まり。SQLでいう行。プライマリキー以外、各項目は独自の固有の属性を持つ事ができる。(テーブルはスキーマレス。属性またはデータ型を事前に定義する必要がない)
- 属性(青枠):各項目は1つ以上の属性で構成される。SQLでいう列。持っている属性は項目によって違っても良い。
このテーブルではプライマリキーがUserID(パーティションキー(後述))となっている。
また、Name、Age、Email、Tel、Hobbiesなどの属性があるが、項目によってはTel属性がない場合や、Hobbies属性を持っていないこともある。

SQLとDynamoDBの用語比較
| SQL | DynamoDB |
|---|---|
| テーブル | テーブル |
| 行 | 項目 |
| 列 | 属性 |
| プライマリキー | プライマリキー |
| インデックス | セカンダリインデックス |
プライマリキーとは
テーブルを作成する際、テーブル名に加えて、テーブルのプライマリキーを指定する必要がある。
プライマリキーはテーブルの各項目を一意に識別するための値。つまり、テーブル内に同じプライマリキーを持つ項目はない。
DynamoDBはプライマリキーを1つの属性にするか2つの属性にするか決める。
1つの属性をプライマリキーにする
- その属性のことをパーティションキーという
- この場合、2つの項目が同じパーティションキー値を持つことはない。
- Usersテーブルで言うと、UserID=001という項目は1つしか存在しない
2つの属性をプライマリキーにする
- 1つ目をパーティションキー、2つ目をソートキーと呼ぶ
- パーティションキー + ソートキーという2 つの属性で構成されたプライマリキー(複合プライマリキーと呼ばれる)
- パーティションキーは複数の項目で同じ値を持つことがある。ただし、パーティションキー+ソートキーの組み合わせが同じ項目はない
- 例えば、以下の例に示したMusicテーブルはパーティションキーがArtistで、ソートキーがSongTitleとなっている。Artist=BUMP OF CHICKENは複数項目取得できるが、Artist=BUMP OF CHICKEN, SongTitle=sailing dayの項目は1つだけ
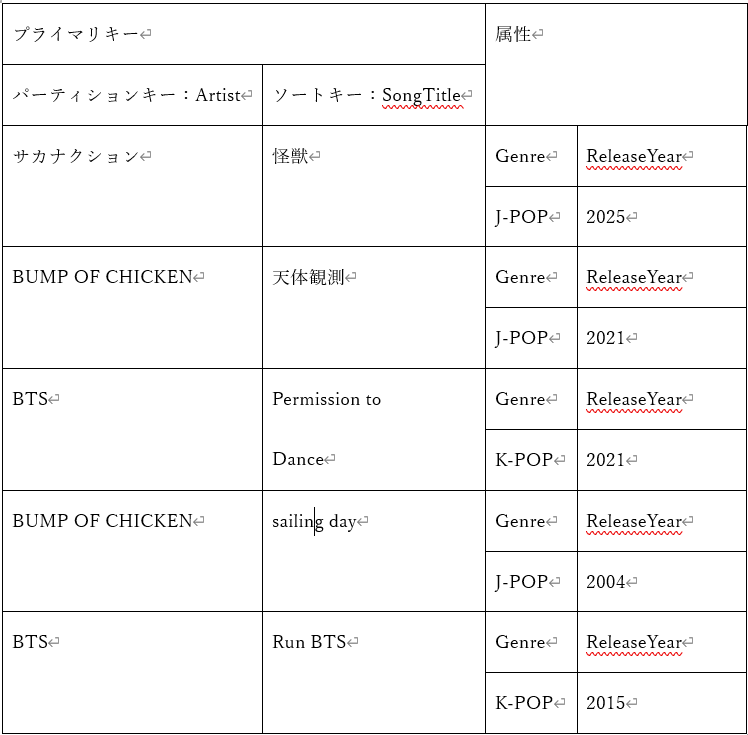
セカンダリインデックス
2種類のセカンダリインデックスをサポートしている。追加することで検索に柔軟性をもたせることができる。
| グローバルセカンダリインデックス(GSI) | ローカルセカンダリインデックス(LSI) | |
|---|---|---|
| 特徴 | ・テーブルのパーティションキーと異なる属性をパーティションキーにできる ・後から追加可能 ・強力な整合性のある読み込みができない | ・パーティションキーはテーブルと同じ ・ソートキーを別の属性にできる ・テーブル作成時にしか定義できない ・強力な整合性のある読み込みができる |
| 例 | パーティションキー:Genre ソートキー:ReleaseYear →「ロックジャンルの曲を発売年順で取得したい」といったクエリが可能 | パーティション:Artist(ベーステーブルと同じ) ソートキー:ReleaseYear →「同じアーティストの曲をリリース順で並べる」といった検索が可能 |
| コスト | ・GSIにもRCU/WCUが必要 | ・RCU/WCUは別途割り当てる必要はない |
DynamoDB Streams
DynamoDBテーブルのデータ変更イベントをキャプチャするオプション。
これらのイベントはほぼリアルタイムに、イベントの発生順にストリームに表示される。
各イベントはストリームレコードによって表される。
DynamoDBで以下のイベントが発生するたびにストリーミングレコードが書き込まれる
| イベント | 取得データ |
|---|---|
| (作成)新しい項目がテーブルに追加された場合 | すべての属性を含む項目全体のイメージ |
| (変更)項目が更新された場合 | 項目で変更された属性についての「前」と「後」のイメージ |
| (削除)テーブルから項目が削除された場合 | 削除される前の項目全体のイメージ |
- 各ストリームレコードにはテーブルの名前、イベントのタイムスタンプ、その他メタデータが含まれる
- 有効期限は24時間で、その後はストリームから自動で削除される。
テーブル内のデータが変更された時にストリームに書き込まれる情報をStreamViewTypeで指定できる
| StreamViewType | 内容 |
|---|---|
| KEYS_ONLY | 変更された項目のキー属性のみ |
| NEW_IMAGE | 変更後に表示される項目全体 |
| OLD_IMAGE | 変更前に表示されていた項目全体 |
| NEW_AND_OLD_IMAGE | 項目の新しいイメージと古いイメージ |
DynamoDB Streamsの使用例
新規登録した顧客に「ようこそ」Eメールを送信する。
会社の顧客情報を含むCustomerテーブルを考える。このテーブルでDynamoDB Streamsを有効化してLambda関数に関連付ける。このテーブルに新規のユーザーが追加されたとき、Lambda関数にストリームレコードが渡されて、EmailAddress属性をもつ項目についてAmazon SESをコールしてアドレスにE-mailを送信する
Time to Live (TTL)
TTLを有効化すると、不要になった項目を、WCUを消費することなく削除できる
例えば、expireAtという属性をTTL属性として設定し、その属性にエポック秒で有効期限を設定すると、有効期限が切れてから数日以内に項目が自動的に削除される
設定方法
- テーブルでTTLを有効化する
- 有効期限を設定する属性を決める(例:expireAt)
グローバルテーブル
複数AWSリージョンにまたがって、自動的にデータを複製・同期するDynamoDBテーブル
例えば、東京リージョンと、オレゴンリージョンに同じテーブルをもたせる
どちらに書き込んでも、自動的にもう一方にレプリケーションされる
→どのリージョンからでも同じデータにアクセスできる
メリット
東京リージョンが落ちても、オレゴンのテーブルでサービス継続可能
日本のユーザーは東京リージョンのテーブルにアクセスし、アメリカのユーザーはオレゴンリージョンのテーブルにアクセㇲ→レスポンスが早い
読み込み / 書き込み
読み込み:DynamoDBテーブルからのデータの取得(読み込み)
書き込み:DynamoDBテーブルへのデータの挿入、更新、削除(書き込み)
- 読み込み/書き込みはアプリケーションのパフォーマンスとコストに影響する。
- 読み込み/書き込みには、様々なタイプがあり、それぞれのオペレーションでユニットを消費する
読み取り整合性 について
読み取る対象4つ
- DynamoDB テーブル
- ローカルセカンダリインデックス(LSI)
- グローバルセカンダリインデックス(GSI)
- ストリーム
2つの読み込み整合性オプション
結果整合性のある読み込み(デフォルト)
全ての読み取りオペレーションのデフォルト。結果整合性のある読み取りでは、直近でテーブルに書き込まれた内容が反映されない場合がある。少し時間が経ってから再度読み取りリクエストをすると最新の項目が取得できる。強力な整合性のある読み込みの半分のコストで済む。
強力な整合性のある読み込み
読み取りオペレーション(GetItem, Query, Scan)にはオプションのConsistentReadパラメーターがある。ConsistentReadをtrueで読み取りオペレーションを実行すると、必ず最新データを取得できる。これが強力な整合性のある読み込み。
ただし、テーブルとセカンダリインデックスでのみサポートされている機能。
(グローバルセカンダリインデックス、DynamoDB Streamでは強力な整合性のある読み込みはサポートされていない)
まとめ
| 読み込み整合性オプション | 対象 | 動作 |
|---|---|---|
| 結果整合性のある読み込み(デフォルト) | DynamoDBテーブル、LSI、GSI、ストリーム | ・最新ではないデータが取得される可能性がある。 ・強力な整合性のある読み込みの半分のコスト |
| 強力な整合性のある読み込み | DynamoDBテーブル、LSI | ・必ず最新のデータを取得する |
キャパシティユニット消費量
読み込みの場合
読み込みタイプ(3種類)ごとにキャパシティユニットの消費量が違う。
| 読み込みタイプ | 4KB以下の項目の読み取りに必要なキャパシティユニット |
|---|---|
| 強力な整合性 | 1 |
| 結果整合性 | 0.5 |
| トランザクション | 2 |
- (例1)GetItem オペレーションでテーブルから10KBの単一の項目を読み込んだ場合、項目のサイズは4KBの倍数まで切り上げられるため、読み込む項目のサイズは12KBとして計算される。
- (例2)BatchGetItemオペレーション(1つ以上のテーブルから最大100個の項目の読み込み)の場合、バッチ内の各項目を個別のGetItemリクエストとして処理する。例えば、1.5KBと6.5KBの2つの項目を読み込んだ場合、読み込む項目のサイズは4KB + 8KBとして計算される。(1.5KB+6.5KB=8KBではない)
- (例3)Queryオペレーションの場合。返されるすべての項目の合計サイズを単一の読み込みオペレーションとして扱う。Queryオペレーションの結果、合計サイズが40.8KBの10項目が返される場合、読み込む項目のサイズは44KBとして計算される。
- (例4)Scanオペレーションの場合、テーブル内の全ての項目を読み込み、そのサイズが読み込む項目のサイズとして計算される。(スキャンにより返される項目のサイズではない)なので、コストが高くつきやすい
書き込みの場合
| 書き込みタイプ | 最大1KBの項目の1回の書き込みに必要なキャパシティユニット |
|---|---|
| 通常の書き込み | 1 |
| トランザクション書き込み | 2 |
*500バイトを書き込みたい場合は、書き込む項目のサイズは1KBに切り上げられ手計算される。
- (例1)PutItemオペレーションの場合。テーブルに項目を書き込む時にすでに項目が存在する場合、このオペレーションによって項目が置き換えられるが、キャパシティユニットの消費量は、置き換え前と置き換え後の2つのうち大きい方となる。UpdateItemオペレーションでも同じで、前の項目サイズと後の項目サイズの大きい方のキャパシティユニットが生じされる。
- (例2)DeleteItemオペレーションの場合。削除する項目のサイズがキャパシティユニットとして計算される。
- (例3)BatchWriteItemオペレーション(1つ以上のテーブルに最大25個の項目を書き込む)の場合。バッチ内の各項目を個別のPutItemまたはDeleteItemリクエストとして処理する。消費キャパシティ料の計算は、各項目のサイズを1KBで切り上げてから合計サイズを計算する。例えば、500バイトと3.5KBの2つの項目を書き込んだ場合、5KB(1KB + 4KB)として計算される。4KB(500バイト + 3.5KB)ではない。
スループットモード
オンデマンドモード
管理が簡単・自動的にスケールする・キャパシティの計画が不要・スケーリングポリシーを気にする必要がない。
書き込み/読み込みの分だけ支払う従量制。
プロビジョンドモード
アプリケーションに必要な1秒あたりの読み込みと書き込みの回数を指定する必要がある。
プロビジョニングしたキャパシティの実際に使用した量ではなく、プロビジョニングした時間単位の読み込みおよび書き込みキャパシティに基づいて課金される。(つまり、使っても使わなくでもプロビジョニング分が必ず課金される。)
使い分け
オンデマンドモード
- リクエストに応じて「使った分だけ」課金
- リクエスト数が多いと、プロビジョンドより高くなりやすい
プロビジョンドモード
- あらかじめ1秒あたりの読み込み/書き込みキャパシティを予約して、その分の料金を支払う
- 使っても使わなくても同じ料金
- 常に一定のリクエストがあるアプリの場合、オンデマンドモードよりも安くなる
その他
- オンデマンドモードからプロビジョンドモードへは切り替え可能。ただし、条件あり。
DynamoDB Accelerator(DAX)
DAXは、インメモリキャッシュを用いて、データへの結果整合性のある読み込みワークロードのアクセス応答時間を、1桁ミリ秒単位からマイクロ秒単位の応答まで短縮する。
特徴
- 最小限の機能変更で実現可能
- 読み込みの多いワークロード・急激に増大するワークロードにおいて、読み込み容量ユニットを必要以上に消費しないのでコストの削減が可能になる
- データの保存時の暗号化をサポート
- データの転送中の暗号化をサポート
最後に
AWS DVA対策として、DynamoDBの機能をまとめてみました。思っていたよりも長くなってしまいました。書いた後に読み返してみましたが、あんまり分かりやすくないなあ。と思いました。なので、AWS DVAの勉強をする際には、この記事で理解するというよりは、すっと頭に入ってこなかった内容=理解が浅いところを追加で調べるという使い方ができると思います!(無理やり)
この記事がどなたかのお役に立てれば幸いです。
もし間違いを見つけた場合は、コメントで教えていただけると助かります。


コメント